

AI models often struggle to address India's distinctive healthcare landscape due to training on predominantly western datasets. These models often miss crucial elements like India's rich linguistic diversity, unique healthcare system dynamics, varied genetic backgrounds, and specific disease prevalence patterns.
To bridge this gap, robust evaluation frameworks are essential, ones that incorporate representative datasets and meaningful metrics tailored to assess AI model performance in diverse healthcare contexts. KARMA-OpenMedEvalKit represents an advancement toward this goal. KARMA serves as an expandable evaluation toolkit designed specifically for assessing AI models in medical applications, featuring multiple healthcare-focused datasets with particular emphasis on the Indian healthcare environment.
This comprehensive approach ensures that AI systems can be properly evaluated for their effectiveness in real-world medical scenarios, particularly those reflecting the complexities and specificities of Indian healthcare delivery.
Alongside KARMA, we are contributing four novel evaluation datasets to the research community, specifically designed for developing and assessing medical large language models (LLMs). Additionally, we are making publicly available two specialised LLMs: one optimised for Medical Automatic Speech Recognition (ASR) in English, and another tailored for medical document comprehension.
These resources represent our commitment to advancing the field by providing researchers and developers with the tools necessary to create more effective and contextually appropriate medical AI systems.
KARMA (/ˈkɑrmə/) stands for Knowledge Assessment and Reasoning for Medical Applications. It provides a unified package for evaluating medical AI systems, supporting text, image, and audio-based models. This extendible framework includes support for 19 medical datasets and offers standardized evaluation metrics commonly used in healthcare AI research, and out of the box support for models like Qwen, MedGemma, IndicConformer, OpenAI, and AWS Bedrock (Anthropic models).
KARMA's registry system allows researchers to integrate their own models and datasets. Models can be added by inheriting from base classes and registering them using the framework's decorator system. Similarly, new datasets can be registered with specified metrics and task types. KARMA also supports custom metrics that are needed to evaluate datasets with specific requirements of post-processing model output, like in the case of Automatic Speech Recognition (ASR) models, where language specific nuances need to be handled before calculating the metrics. Beyond this, KARMA also has a model output caching mechanism to store the model’s output and re-compute metrics or re-use the outputs as needed.
KARMA can be used through the CLI as well as a package to import. The CLI also has an interactive mode to select the required model and datasets for running the evaluation.
KARMA includes evaluation support for medical datasets with following task types:
View complete dataset catalog. Adding new datasets involves just adding a single new file to KARMA read further in the documentation here.
Browse all supported models. Here’s how you can add your own models to KARMA.
All HuggingFace metrics are supported out of the box, and custom metrics like Healthbench’s rubric-based evaluation have also been added.
We also introduce two new ASR metrics - Semantic WER and entity/keyword WER, to address the challenges in evaluating ASR models in the health care use case. Semantic WER measures transcription accuracy based on semantic meaning, handling numerals, synonyms, abbreviations, and code-switching. Keyword WER evaluates the accuracy of critical medical terms like drug names, dosages, and vital signs within transcripts. Read more about these metrics here.
In addition to KARMA, we also release 2 models and 5 evaluation datasets already integrated within KARMA.
We are launching these datasets along with KARMA
All the datasets have been curated by the medical-doctor team at EkaCare. All datapoints undergo rigorous PII removal to ensure complete privacy. Read more about these datasets here.
Along with our datasets, we are also releasing 2 models from our Parrotlet series in the public domain licensed under MIT.

The framework is available as a Python package and can be installed via pip
pip install karma-medeval$ karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa –max-samples
{
"openlifescienceai/pubmedqa": {
"metrics": {
"exact_match": {
"score": 0.3333333333333333,
"evaluation_time": 0.9702351093292236,
"num_samples": "3"
}
},
"task_type": "mcqa",
"status": "completed",
"dataset_args": {},
"evaluation_time": "7.378399848937988"
},
"_summary": {
"model": "Qwen/Qwen3-0.6B",
"model_path": "Qwen/Qwen3-0.6B",
"total_datasets": 1,
"successful_datasets": 1,
"total_evaluation_time": 7.380354166030884,
"timestamp": "2025-07-22 18:43:07"
}
}Complete documentation, installation guides, and examples are available at https://karma.eka.care. Source code is hosted on GitHub at https://github.com/eka-care/KARMA-OpenMedEvalKit.
KARMA aims to provide researchers and healthcare organizations with consistent evaluation tools for medical AI development, supporting reproducible research and systematic model comparison across different medical domains.
KARMA is released under the MIT License. We are looking forward to building India medical evaluations with the community. The datasets, models supported through KARMA will be evolving.
Get Started
pip install karma-medeval run your first evaluation in 5 minutes
Evaluation and benchmarking of both the models released by EkaCare and its internal systems is done using KARMA framework. Below we present our evaluation benchmarking results done using KARMA on four datasets mentioned above.
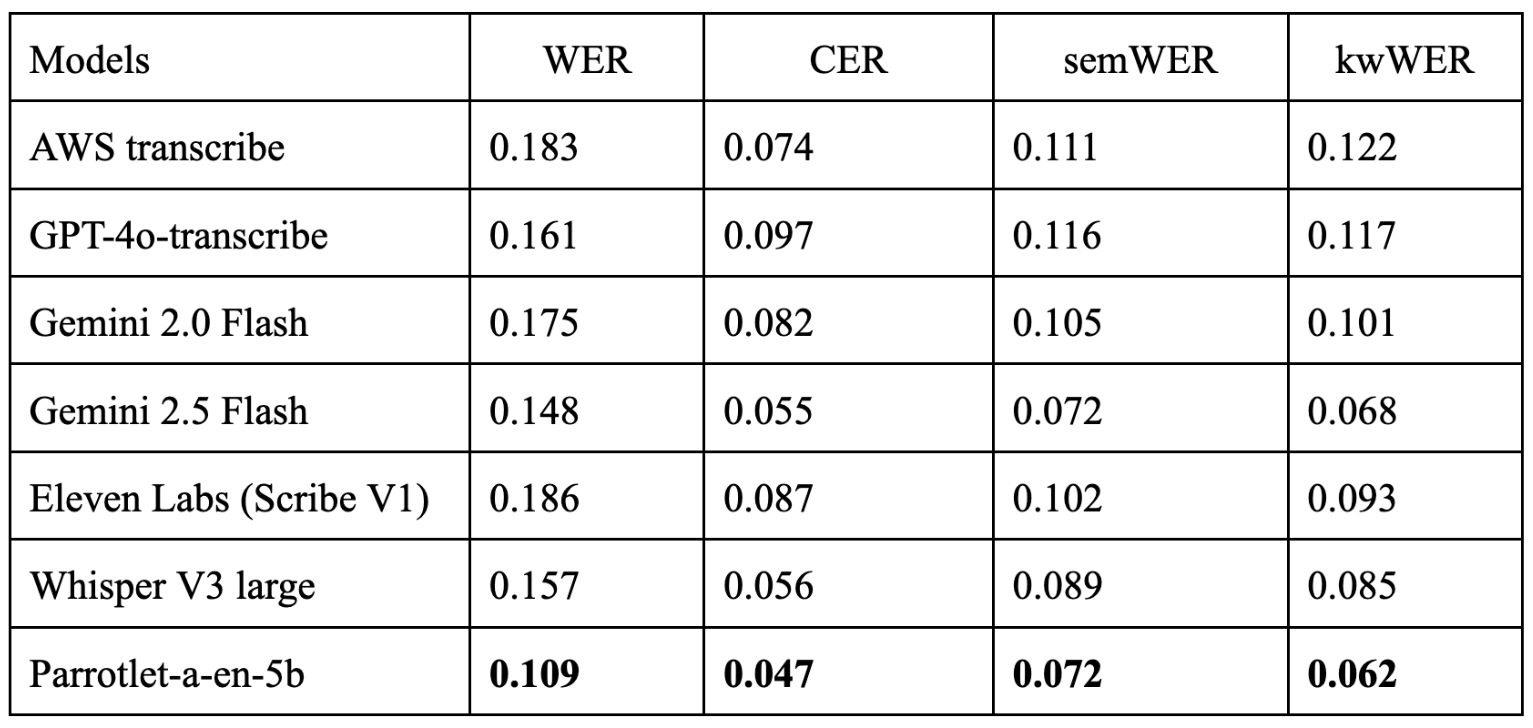
Comparison of various ASR models on english subset of this dataset.
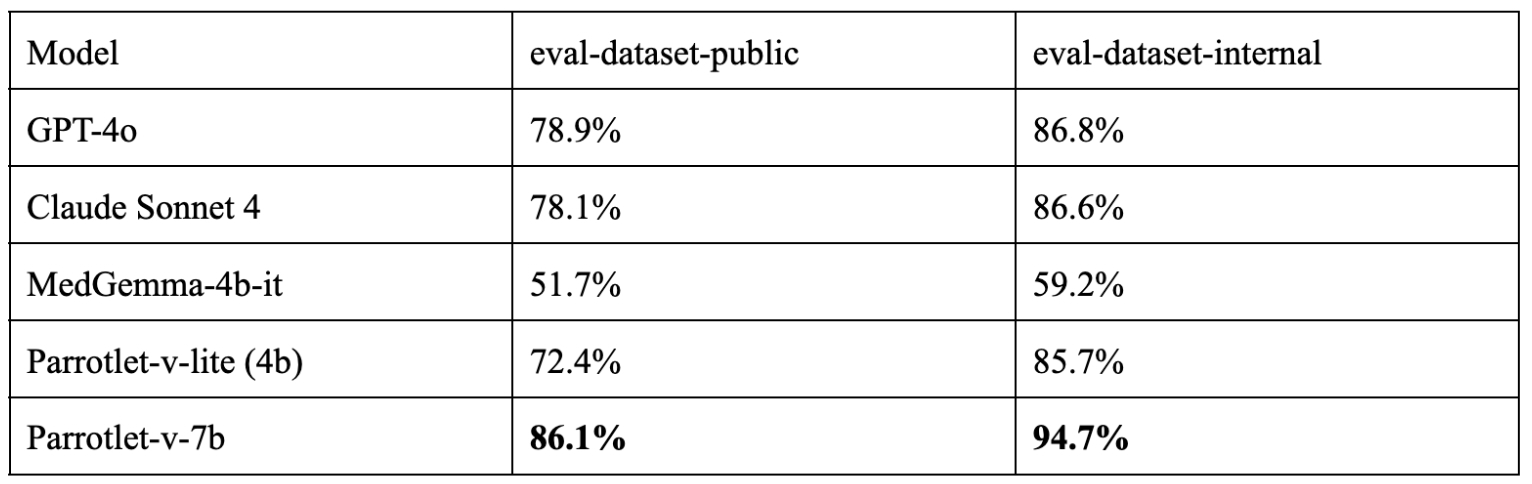
Comparison of various vision models on this dataset.
Comparison of different SOTA models and EkaCare's scribe on this dataset.
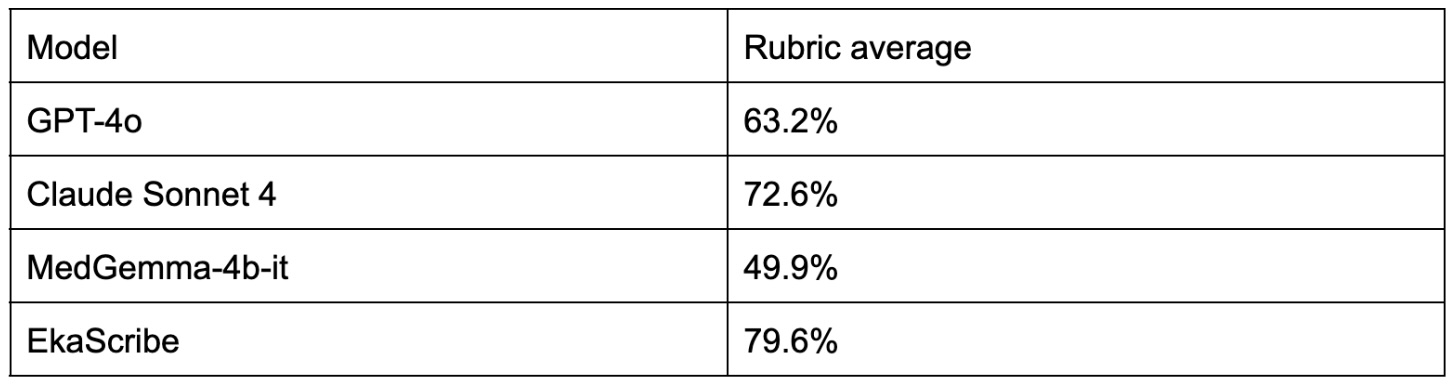
EkaScribe is EkaCare's medical scribe assistant available on chrome store.
Comparison of different SOTA models and EkaCare's DocAssist on this dataset.
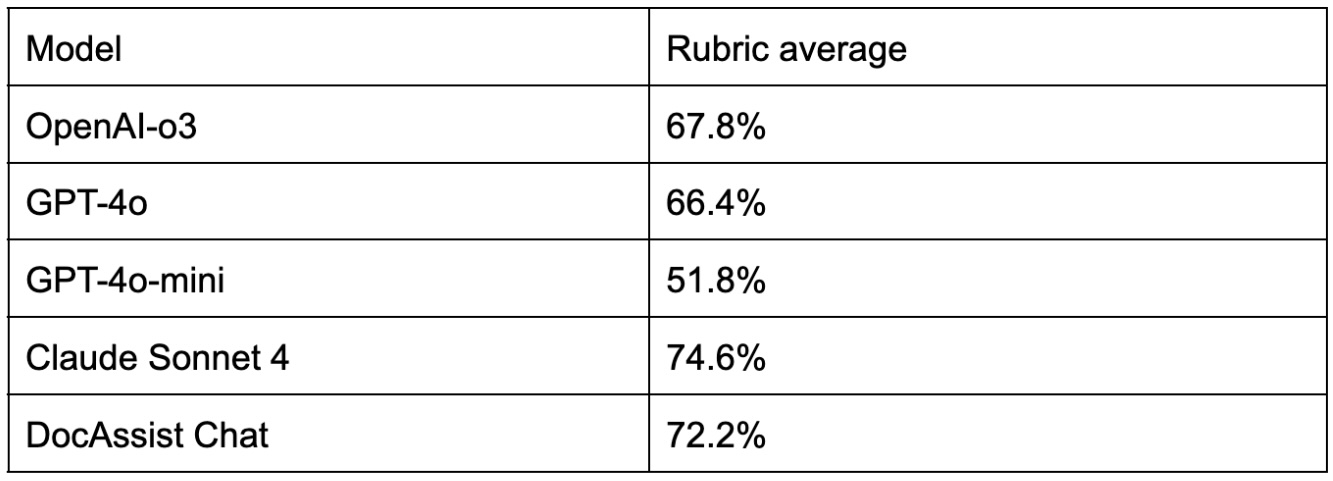
DocAssist is EkaCare's AI assistant for doctors available on both android and iOS applications, as well as on its EMR tool.
Contribute Data: Integrate your datasets into Karma with addition of just a single file addition https://karma.eka.care/user-guide/add-your-own/add-dataset/
Join Discussion: Connect with 500+ researchers in our Developer Discord
Report Issues: Help us improve on GitHub Issues
Get Support: Reach our team at developer@eka.care
%20(1).jpg)

.jpg)
%20(1)%20(1).jpg)