

Medical scribe systems can dramatically accelerate India's healthcare digitization by eliminating the documentation burden that currently hinders adoption. These systems can automatically convert doctor-patient conversations into structured digital records in real-time, removing the need for manual data entry that healthcare providers find time-consuming and disruptive to patient care.
One of the fundamental challenges in automatic speech recognition (ASR) applications is handling out-of-vocabulary words—a problem that becomes particularly acute in medical contexts. While reasonably accurate ASR models exist, including open-weight alternatives, their performance on clinically rich real-world consultations remains significantly limited. The challenge intensifies in the Indian context due to the prevalence of localised medical concepts such as branded drug names, colloquial expressions of medical concepts. There is a clear need to develop specialised ASR models that can accurately recognise medical vocabularies within India's healthcare environment.
In this blog, we introduce one of our latest developments, a Speech Large Language Model (LLM) specifically designed for transcribing medical speech in Indian English. We are open-sourcing this specialised model to advance healthcare digitisation across the country. Our architecture combines a robust speech encoder with a custom multimodal projection layer and a domain-specific language decoder, enabling accurate and context-aware transcription of clinical conversations, medical dictations, and patient interactions. This represents a crucial step toward making healthcare more accessible, efficient, and digitally integrated across India's diverse medical landscape.
Domain Adaptation Without Speech Data: The multimodal approach enables training on extensive medical text corpora without requiring corresponding audio data. This is particularly valuable given the scarcity and expense of creating high-quality medical speech datasets, specifically in low resource languages in India. By leveraging text-only medical data during fine-tuning, we can incorporate vast amounts of domain knowledge that would be impractical to collect in audio format.
Pre-trained Domain Expertise: The architecture allows us to utilize existing domain-specific language models as decoders. Our implementation employs MedGemma 3 4B IT, which has been pre-trained on over 2.5 billion tokens of medical text. This pre-trained medical knowledge significantly enhances transcription accuracy for clinical terminology without starting from scratch.
Multilingual Medical Coverage: A multilingual decoder can handle multiple Indian languages while leveraging the fact that medical terminology is predominantly English-based. This unified approach provides comprehensive coverage across linguistic boundaries, making it particularly effective for India's multilingual healthcare environment where practitioners often code-switch between local languages and English medical terms. However, in this release we only train and evaluate on english datasets.
By training only a lightweight projection layer between the frozen speech encoder (Whisper V3 Large) and the pre-trained medical decoder, Parrotlet-A achieves high accuracy with minimal computational overhead while addressing the unique challenges of Indian medical transcription.
Parrotlet-a-en is engineered with a multimodal architecture comprising three core components:
For the CPT stage we use parameter efficient LoRA technique with rank 128 and alpha of 32. In addition to using LoRA adapters we also fully train the text embedding layer and language modelling head. We use a learning rate of 1e-5 with cosine decay type and bf16 precision. Later the LoRA adapter layers were merged to the base model.
Evaluation of this model and benchmarking with other SOTA models is done using KARMA evaluation toolkit. The error rates mentioned here are over aggregated word and character counts across the entire dataset and not mean of per file level metrics.
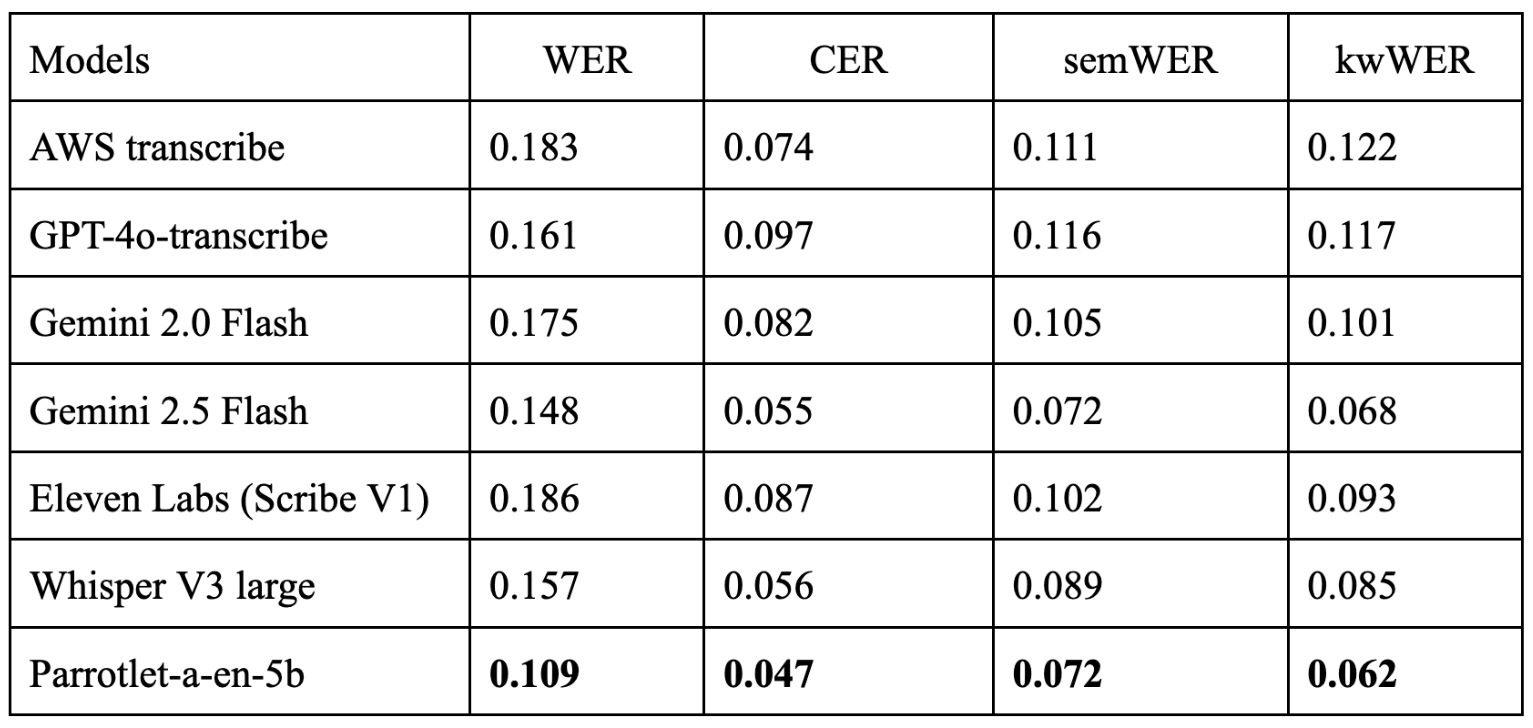
semWER and kwWER are explained in depth in this blog.
The evaluation results for Parrotlet-a-en-5b, derived from the Eka Med ASR English benchmark, demonstrate impressive performance with a Word Error Rate (WER) of 0.109, Character Error Rate (CER) of 0.047, Semantic WER (semWER) of 0.072, and Medical Entity Keyword WER (kwWER) of 0.062. This outperforms established models such as GPT-4o, Gemini 2.0/2.5 Flash, and Eleven Labs. Our model effectively handles Indian English accents and complex medical terminology, including branded drug names. The model maintains low error rates for semantic content and medical keywords, ensuring accurate clinical documentation.
A key advantage is its efficient design, training only a lightweight projection layer while leveraging pretrained components, which minimizes computational demands and supports real-time application even in resource-constrained settings. By open-sourcing Parrotlet-a-en-4b, we invite the research and development community to build upon these models, developing innovative applications to improve patient care. In addition to this model, we also make our EkaScribe application available through API.
%20(1).jpg)

.jpg)
%20(1)%20(1).jpg)