
The digitisation of healthcare in India presents unique challenges that require specialised AI solutions tailored to the Indian healthcare ecosystem. Recognising the critical need for robust evaluation frameworks in medical AI, EkaCare is proud to announce the release of four evaluation datasets specifically designed for the Indian healthcare context. These datasets address key areas in healthcare data processing: medical records parsing, structured clinical note generation, automatic speech recognition, and medical summarisation.
These datasets represent our initial steps toward establishing a standardised healthcare AI evaluation framework in India, providing researchers, healthcare institutions, and AI developers with essential tools to evaluate systems that can truly serve the diverse needs of Indian healthcare. All datasets have been meticulously curated from internal sources, including our team members, internal medical professionals, sales demonstration sessions, and consenting EkaCare Personal Health Record (PHR) app users, ensuring complete anonymisation and de-identification of all medical records. Due to these factors, the size of these datasets are also limited.
Download dataset (HuggingFace | AIKosh)
The Eka Medical ASR Evaluation Dataset enables assessment of automatic speech recognition systems designed to transcribe medical speech into accurate text—a fundamental component of any medical scribe system. This dataset captures the unique challenges of processing medical terminology, particularly branded drugs, which is specific to the Indian context.
The dataset comprises over 3,900 curated audio recordings featuring medical terminology delivered in various speaking styles, including isolated medical entities, narrated medical sentences, and impromptu medical conversations. The dataset includes approximately 3,600 English recordings and 320 Hindi recordings. We intend to keep improving and growing this dataset for different languages and scenarios.
All audio recordings capture natural speech patterns, ensuring realistic evaluation scenarios. A significant portion of the dataset originates from EkaCare's internal team members through narrated medical text sessions and recorded EkaScribe demonstration sessions with our internal medical professionals. Additional high-quality content was sourced from speakers across five different medical colleges, providing diverse regional accents and speaking styles representative of India's medical education landscape.
This dataset is valuable for developers building and evaluating voice-enabled healthcare applications, and medical documentation systems that rely on speech-to-text functionality. Healthcare institutions implementing AI-powered scribe solutions will find this dataset essential for evaluating system performance across diverse Indian linguistic contexts.
These numbers are only for the english subset of the dataset using various models listed below
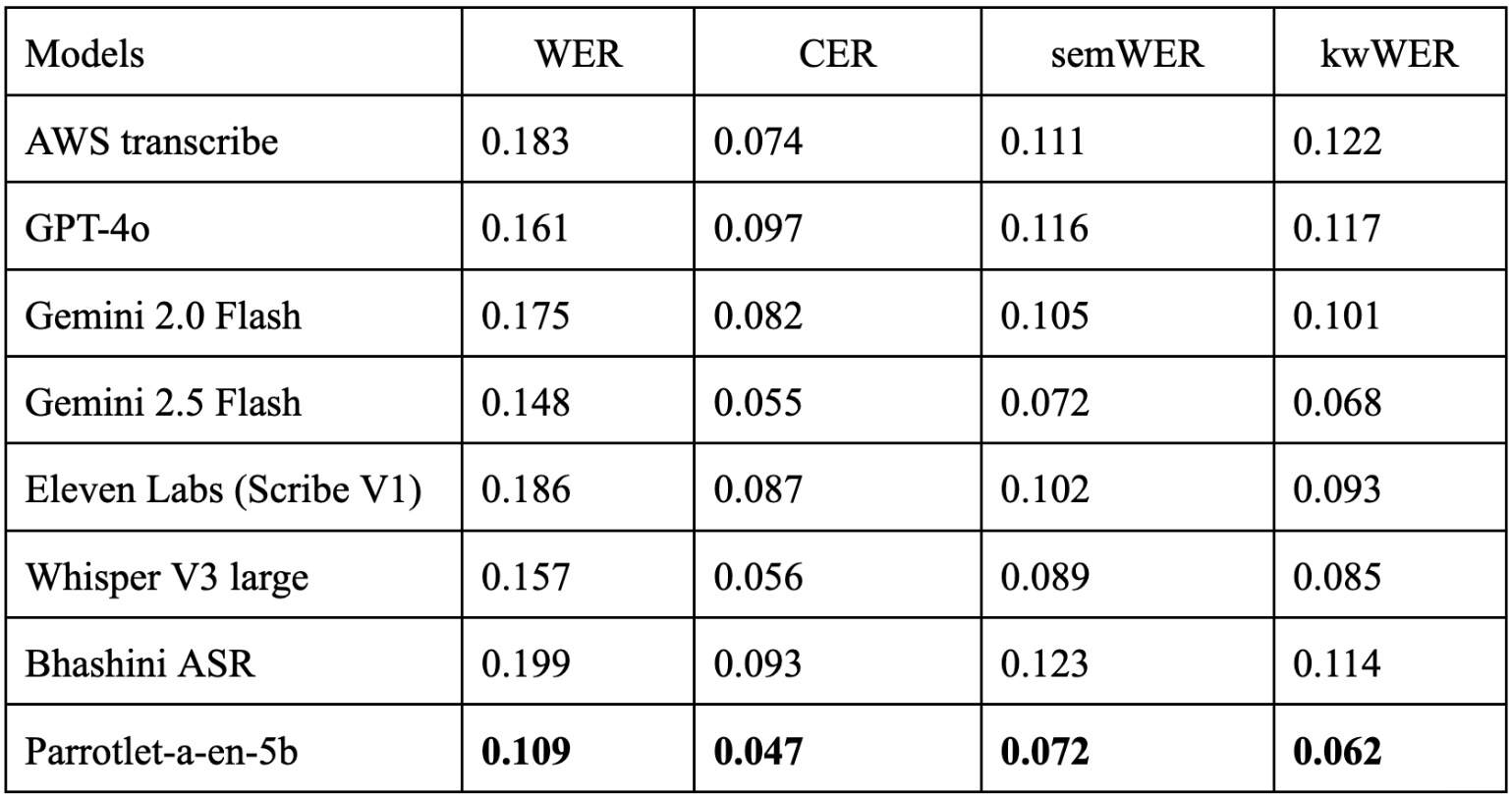
Bhashini ASR API used ai4bharat/whisper-medium-en--gpu--t4 endpoint.
The best performing model Parrotlet-a-en-5b is made publicly available here.
Download dataset (HuggingFace | AIKosh)
The Eka Medical Records Parsing Dataset enables evaluation of AI systems designed to extract structured information from unstructured medical documents, enabling true digitisation of healthcare data while maintaining clinical accuracy.
The dataset (referred as eval-dataset-public) comprises 288 carefully selected images of laboratory reports and prescriptions representing diverse formats and templates encountered in Indian healthcare settings. This variety ensures a comprehensive evaluation of parsing systems across different document types and layouts.
All medical documents included in this dataset are sourced exclusively from EkaCare’s PHR application and through its internal users. Every document undergoes rigorous personally identifiable information (PII) redaction processes to ensure complete privacy protection. Ground truth labelling is meticulously performed by EkaCare's internal medical team, guaranteeing clinical accuracy and relevance.
This dataset uses a rubric-based evaluation system with large language models acting as evaluators. Originally developed by OpenAI for HealthBench, we have adapted and expanded this approach across multiple datasets in our collection. This method effectively tackles the difficult problem of measuring extraction accuracy across diverse document types, where conventional alignment-based metrics often prove inadequate.
The evaluation rubrics are automatically created using a state-of-the-art LLM utilising ground truth structured JSON data that was carefully annotated by medical experts. Each rubric consists of an objective question designed for binary true/false assessment by an LLM judge. The final score for each dataset entry represents the average of all true/false evaluations across the complete set of rubrics for that specific data point.
This result is obtained using GPT-4o as the judge.
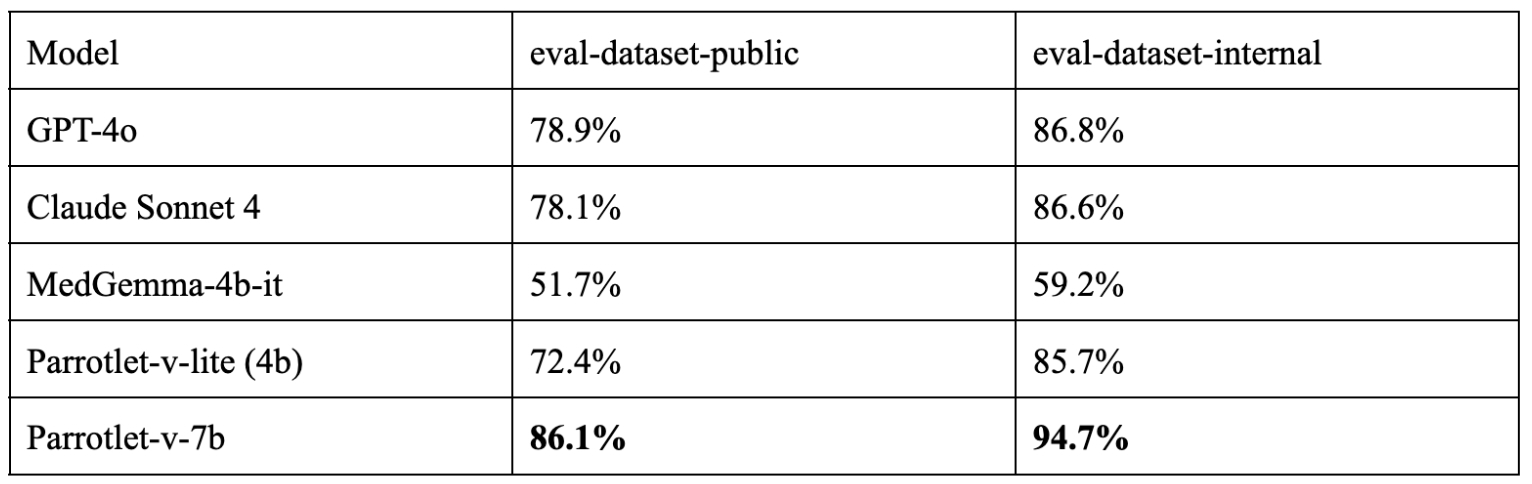
Parrotlet-v-lite-4b is made publicly available here.
Download dataset (HuggingFace | AIKosh)
The Eka Structured Clinical Note Generation Dataset facilitates evaluation of medical scribe systems capable of transforming transcribed medical conversations into structured, entity-level medical records. This dataset addresses one of the most challenging aspects of healthcare AI: understanding and organising complex medical information into structured formats.
Comprising over 156 meticulously transcribed medical conversations between EkaCare's internal doctors and team members serving as patients, this dataset captures diverse clinical interaction patterns. These transcriptions span three languages; English, Hindi and Marathi. Each transcription includes comprehensive ground truth JSON annotation containing entity-level structuring of diverse medical concepts, including dosage instructions, medical advice, symptoms, diagnoses, and treatment recommendations.
This dataset evaluates the ability of AI systems to transform unstructured medical narratives into structured clinical records that can be readily integrated into an electronic health record (EHR) system. An internal team of doctors meticulously converted each case into structured medical notes following a standardized schema—including fields such as symptom, diagnosis, clinical notes, labs prescribed, and lab results—using EkaCare’s EMR platform.
To objectively assess the fidelity of AI-generated structured outputs, we developed a rubric-based evaluation framework. These rubrics are automatically generated using an LLM, which is prompted with the structured ground truth JSON data annotated by the doctor team. Each rubric focuses solely on the presence and correctness of key medical entities in the model output, ensuring flexibility in linguistic phrasing while preserving strict adherence to clinical content.
Evaluation is conducted using a binary true/false scoring for each rubric criterion, where an LLM-based grader determines whether the AI-generated output satisfies each criterion. For each datapoint, the score is the average of true/false evaluations across all applicable criteria. This setup offers a scalable and objective method for benchmarking AI performance, while accommodating the diverse ways in which clinical information can be validly expressed.
These results are obtained using OpenAI’s GPT-4o model as LLM as the judge.
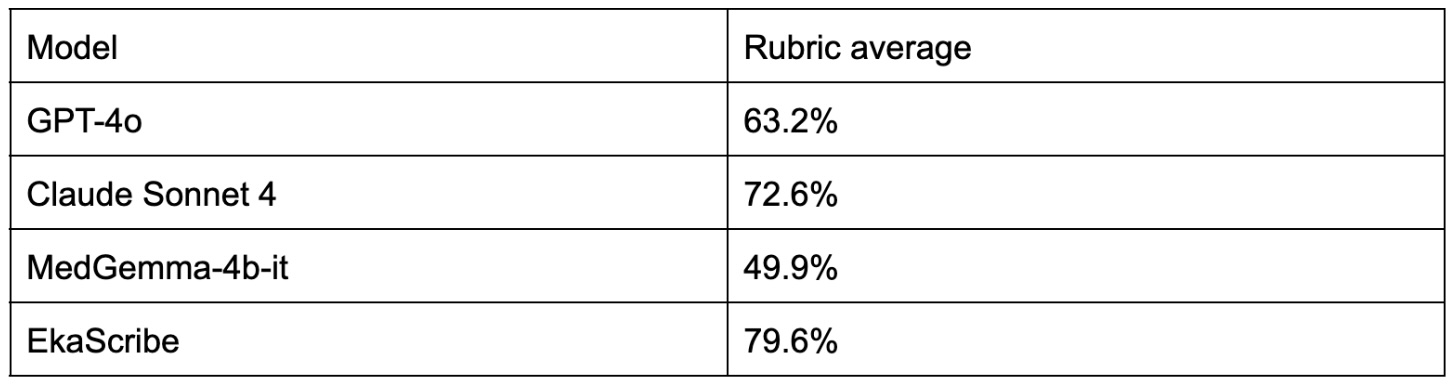
EkaScribe is EkaCare's medical scribe assistant available on chrome store.
Download dataset (HuggingFace | AIKosh)
The Eka Medical Summarisation Dataset addresses the critical need for intelligent processing of extensive medical histories, enabling healthcare professionals to quickly identify key health aspects requiring attention. This capability is particularly valuable in India's high-volume healthcare settings where time efficiency directly impacts patient care quality.
This dataset contains 58 comprehensive and varied medical cases collected from consultations between EkaCare's internal medical team and the company's employees and their family members. Each case provides a complete view of a patient's medical journey, including vital sign trends and historical health context. The dataset is designed to evaluate AI models on their ability to generate concise, clinically meaningful summaries that emphasize the most relevant aspects of care from the most recent six months of each case.
Every case in this dataset reflects real-world clinical complexity while maintaining the highest standards of data privacy. All personal identifiers have been thoroughly removed through a comprehensive anonymization process, ensuring complete PII elimination without compromising the clinical integrity or accuracy of the cases. Great care has been taken to preserve the authenticity and nuances of these consultations, enabling the dataset to serve as a reliable benchmark for summarization tasks in healthcare AI.
Given the free-text nature of clinical summaries, this dataset employs the rubric-based evaluation methodology similar to other benchmarks in the collection. This offers structured reproducible framework and enables objective and consistent assessment of model outputs.
The ground truth clinical summaries were carefully curated by an internal medical team, capturing nuanced, clinically salient information from each patient's recent medical journey. Rubrics were automatically generated by SOTA LLMs by leveraging these annotated clinical summaries. LLM was instructed to create rubric around objective questions on whether the summaries to be evaluated included the key clinical elements present in the ground truth, such as relevant symptoms, diagnoses, investigations, treatments and trends. This rubric-based approach allows for granular evaluation of clinical relevance, completeness, and fidelity, even in the face of varied language or phrasing across different AI systems.
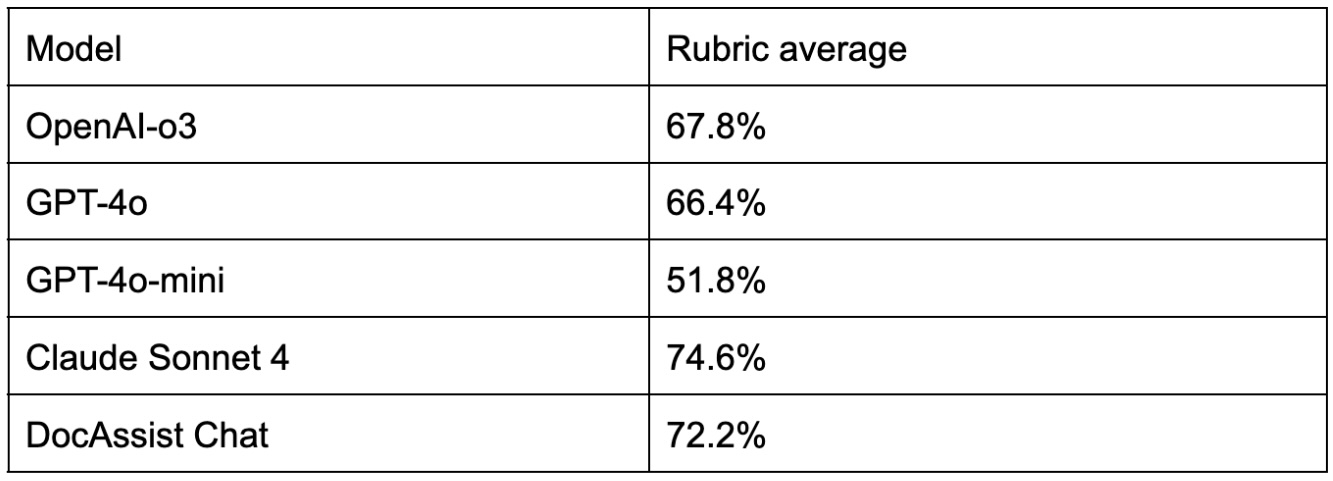
DocAssist is EkaCare's AI assistant for doctors available on both android and iOS applications, as well as on its EMR tool.
In addition to the four original EkaCare datasets described above, we also share the Indic version of MedMCQA described below.
Download dataset (HuggingFace | AIKosh)
The MedMCQA - Indic dataset provides a solution for evaluating AI models' performance on medical content across multiple Indian languages. Building on the well-established MedMCQA benchmark, this dataset enables evaluation of medical knowledge of an LLM in regional languages.
MedMCQA has become a standard evaluation dataset for medical AI, containing over 194,000 high-quality multiple-choice questions from AIIMS and NEET PG entrance exams. The dataset covers 2,400 healthcare topics across 21 medical subjects with good topical diversity and an average token length of 12.77. However, the original dataset is entirely in English.
To enable evaluation of AI models on medical content in Indian languages, we have translated the MedMCQA validation set—comprising 4,180 samples—into 11 Indian languages using the Llama 4 Maverick 17B 128E model. This provides a practical tool for assessing whether language models can handle medical questions presented in different Indian languages.
This dataset is useful for developers testing medical AI systems intended for regional markets, educational technology companies creating multilingual medical learning platforms, and researchers studying language model performance across Indian languages in medical contexts. It offers a simple way to evaluate whether existing medical AI capabilities transfer effectively across India's linguistic diversity.
These five comprehensive evaluation datasets represent EkaCare's commitment to developing robust, domain-appropriate healthcare technology solutions specifically tailored for the Indian healthcare ecosystem. By making these carefully curated datasets available to the broader healthcare AI research community, EkaCare aims to accelerate innovation in Indian healthcare digitisation while establishing rigorous evaluation standards.
Our approach ensures that AI systems are developed and validated using proper evaluation frameworks that account for the unique linguistic, clinical, and operational challenges inherent in the Indian healthcare environment. These datasets serve as foundational tools for building healthcare AI solutions that can truly transform patient care delivery across India's diverse healthcare landscape.
Through this initiative, EkaCare continues to lead the advancement of healthcare AI in India, fostering collaboration between researchers, healthcare institutions, and technology developers to create solutions that genuinely serve the needs of Indian patients and healthcare providers.
All the datasets mentioned here are available in this collection.
Annotators:
Dr Anushree Rana
Dr Rajshree Badami
Dr Arun Kumar R
Neha Shrivastava
Dr Kashika Singh
Dr Rishi Srivathsav
Dr Arun Kumar
Dr Kumar Sarthak
Dr Shikha alias Sharda Raghunath Dessai
Yashasvee Singh
Soumya Anshu
Rushabh Vasani
Vasanth Murukuri
Dr Sanjana SN
Medical Students, Faculty and Staff:
1. Father Muller Medical College and Hospital , Mangalore
2. Subbaiah Institute of Medical Sciences and Research Centre, Shivamogga
3. Kempegowda Institute of Medical Sciences, Bengaluru
4. J.J.M Medical College, Davanagere
5. Rajarajeswari Medical College and Hospital , Bengaluru
%20(1).jpg)

.jpg)
%20(1)%20(1).jpg)